Clustering vs. Segmentation
Techniques in Data Analysis
1. Clustering
Clustering is an unsupervised learning technique used to group similar data points based on their features without predefined labels. It’s primarily a data-driven approach where the algorithm finds patterns and groups in the data.
Key Characteristics:
• Data-Driven: No predefined groups; the algorithm determines the groups.
• Goal: To identify inherent patterns or structures in the data.
• Use Case: When you don’t know the number or type of groups in advance.
Algorithms:
• K-Means Clustering: Groups data into k clusters by minimizing within-cluster variance.
• Hierarchical Clustering: Creates a tree-like structure (dendrogram) of clusters.
• DBSCAN: Groups data points based on density, useful for irregularly shaped clusters.
• Gaussian Mixture Models (GMM): Assumes data is generated from a mixture of Gaussian distributions.
Examples:
• Grouping customers based on purchasing behavior.
• Clustering genes in biological data.
• Identifying patterns in text data.
Output:
• Data points assigned to clusters (e.g., Cluster 1, Cluster 2, etc.).
• Often used as a preprocessing step for further analysis or modeling.
2. Segmentation
Segmentation refers to the process of dividing a dataset or population into distinct, predefined segments based on certain criteria or goals. Unlike clustering, segmentation often starts with domain knowledge or predefined categories.
Key Characteristics:
• Goal-Driven: Often tied to a specific business goal or domain requirement.
• Supervised or Rule-Based: May use labels, thresholds, or business logic to define segments.
• Use Case: When you already have a clear understanding of how to divide your data.
Methods:
• Rule-Based Segmentation:
• Example: Segmenting customers based on age, income, or spending habits using predefined thresholds.
• Supervised Learning:
• Example: Training a classifier to segment users based on historical data.
• Clustering-Based Segmentation:
• Use clustering as a first step and then refine segments based on business criteria.
Examples:
• Marketing segmentation: Dividing customers into segments like “high spenders,” “new customers,” or “churn risks.”
• Image segmentation in computer vision: Partitioning an image into regions for object recognition.
• Geographic segmentation: Grouping areas by demographics or buying behavior.
Output:
• Well-defined segments (e.g., “Low Income, High Spend” vs. “High Income, Low Spend”).
• Often directly actionable in business or analysis.
Key Differences
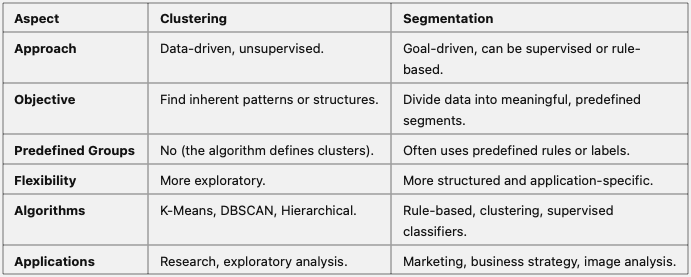
Relationship Between Clustering and Segmentation
• Clustering as a Step for Segmentation:
•Clustering can serve as the first step in segmentation by identifying initial groups, which are later refined using domain knowledge or rules.
• Segmentation for Business Action:
• Clustering helps discover patterns, while segmentation focuses on creating actionable groups aligned with business goals.
Example Use Case
Clustering:
• A retailer wants to explore hidden customer groups based on spending patterns. They use K-Means clustering and find three clusters:
1. Budget Shoppers
2. Regular Shoppers
3. Premium Shoppers
Segmentation:
• The retailer refines these groups into actionable segments:
• Premium Shoppers: Target with luxury product campaigns.
• Budget Shoppers: Offer discounts and budget products.
• Regular Shoppers: Encourage loyalty through rewards programs.