Gradient Boosting Machine (GBM)
GBM, applications, and other MLs’ comparisons
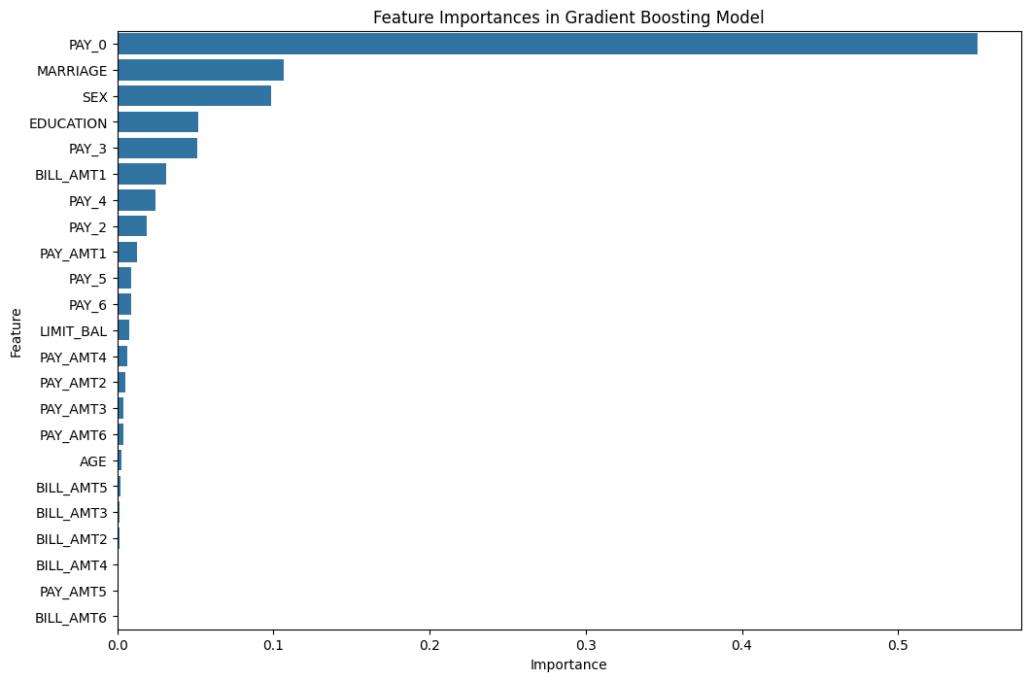
Gradient Boosting Machine (GBM) is an ensemble learning technique that builds a model in a stage-wise fashion from multiple weak learners, typically decision trees, and optimizes for a loss function. The basic idea is to combine the predictions of several base estimators to improve robustness over a single estimator.
How GBM Works:
- Initialization:
- Start with an initial model, often a simple model that predicts the mean of the target variable.
- Iterative Learning:
- At each iteration, a new tree (weak learner) is trained to predict the residuals (errors) of the previous model.
- The new tree’s predictions are added to the previous model’s predictions to form an updated model.
- The process repeats, with each new tree correcting the errors of the combined previous models.
- Optimization:
- GBM minimizes the loss function using gradient descent. The residuals represent the gradient of the loss function, and the algorithm adjusts the model to reduce these residuals.
Applications of GBM:
- Classification and Regression:
- GBM can be used for both classification and regression tasks. It’s commonly used in credit scoring, disease diagnosis, fraud detection, and customer churn prediction.
- Time Series Forecasting:
- GBM can be adapted for time series forecasting tasks by treating the time series as a regression problem.
- Ranking:
- It is used in ranking tasks, such as in search engines and recommendation systems.
Why Use GBM?
- High Predictive Power:
- GBM models often achieve high accuracy and can outperform simpler algorithms like linear regression and single decision trees.
- Flexibility:
- It can handle various types of data (numerical, categorical) and different loss functions (regression, classification, ranking).
- Handling Complex Relationships:
- GBM can capture complex patterns and interactions between features.
Sample codes of Gradient Boosting Machine (GBM)
from imblearn.over_sampling import SMOTEfrom sklearn.ensemble import GradientBoostingClassifierfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import classification_report, accuracy_score, confusion_matrix
# Assuming your dataset is loaded into df# Prepare the data for modelingX = df.drop(['ID', 'default payment next month'], axis=1)y = df['default payment next month']
# Split the data into training and testing setsX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Apply SMOTE to balance the datasetsmote = SMOTE(random_state=42)X_train_resampled, y_train_resampled = smote.fit_resample(X_train, y_train)
# Implement GBM modelgbm_model = GradientBoostingClassifier(random_state=42)gbm_model.fit(X_train_resampled, y_train_resampled)
# Make predictionsy_pred_gbm = gbm_model.predict(X_test)
# Evaluate the modelprint("GBM Accuracy:", accuracy_score(y_test, y_pred_gbm))print("GBM Classification Report:")print(classification_report(y_test, y_pred_gbm))print("GBM Confusion Matrix:")print(confusion_matrix(y_test, y_pred_gbm))
Comparing GBM with Other Machine Learning Models
- Random Forest vs. GBM:
- Random Forest:
- Ensemble of decision trees trained independently.
- Reduces variance by averaging multiple trees.
- Less prone to overfitting than individual decision trees.
- Easier to tune and parallelize.
- GBM:
- Ensemble of decision trees trained sequentially.
- Reduces bias by focusing on residual errors.
- Often achieves higher accuracy but is more prone to overfitting.
- More complex to tune due to the sequential nature of training.
- Random Forest:
- XGBoost vs. GBM:
- XGBoost:
- An optimized version of GBM with improvements in speed and performance.
- Includes regularization to reduce overfitting.
- Supports parallel processing and handles missing values efficiently.
- GBM:
- Standard implementation of gradient boosting.
- Slower and may require more manual tuning compared to XGBoost.
- XGBoost:
- LightGBM vs. GBM:
- LightGBM:
- A gradient boosting framework that uses a histogram-based approach to speed up training.
- Better for large datasets with a high number of features.
- Often faster and more scalable than traditional GBM.
- GBM:
- Standard gradient boosting, slower on large datasets.
- Less efficient with high-dimensional data.
- LightGBM:
- AdaBoost vs. GBM:
- AdaBoost:
- Another boosting algorithm focusing on misclassified instances.
- Simpler than GBM but can be less powerful.
- GBM:
- Focuses on minimizing a loss function using gradient descent.
- Often achieves higher accuracy and can handle complex relationships better.
- AdaBoost:
How to Compare GBM with Other Models:
- Performance Metrics:
- Use metrics like accuracy, precision, recall, F1-score for classification tasks.
- Use metrics like RMSE, MAE, R² for regression tasks.
- Cross-Validation:
- Use cross-validation to assess the generalizability of the model. This helps in comparing the performance of different models more robustly.
- Hyperparameter Tuning:
- Compare models after tuning their hyperparameters to ensure each model is performing optimally.
- Execution Time and Scalability:
- Evaluate the time taken to train and predict, especially on large datasets.
- Interpretability:
- Consider the ease of interpreting the model. Simpler models like linear regression or decision trees are easier to interpret than complex models like GBM.
- Handling Missing Values and Outliers:
- Evaluate how well each model handles missing values and outliers.