Heart failure is a prevalent and severe condition, contributing significantly to morbidity, mortality, and healthcare costs worldwide. Early detection and accurate prediction of heart failure are critical for improving patient outcomes, enabling timely interventions, and optimizing healthcare resources. Despite advancements in medical science, current diagnostic methods often fail to identify high-risk patients in a timely manner, leading to delayed treatments and increased complications.
This research aims to develop and implement advanced machine learning (ML) and deep learning (DL) models to enhance the early detection and prediction of heart failure using data from a Heart Study organization. By leveraging this extensive dataset, which includes detailed medical histories, clinical measurements, and lifestyle factors, the study seeks to identify novel biomarkers and patterns indicative of heart failure onset and progression.
Below are a few factors have been identified:
Featured Factor Importances
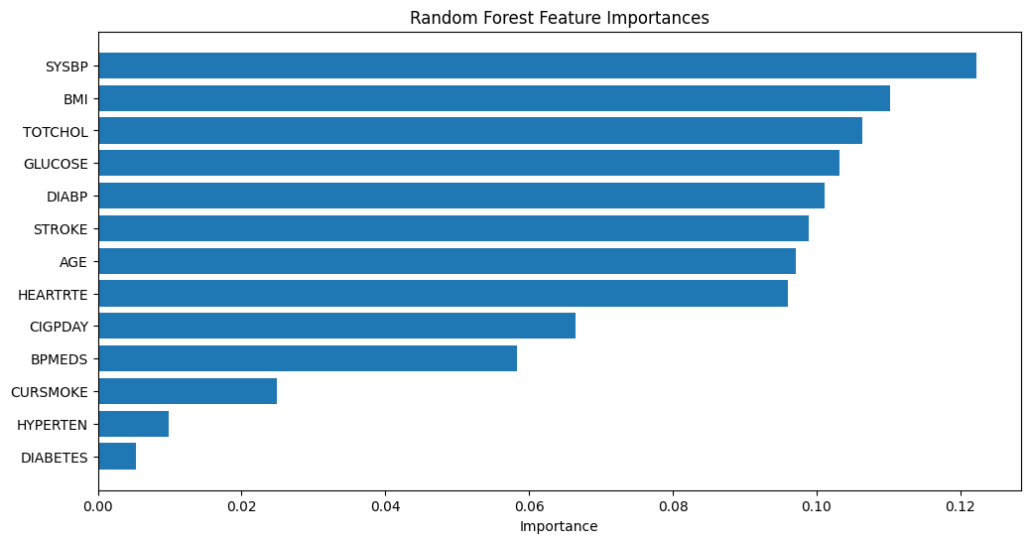
The feature importance chart highlights which factors (features) are most influential in predicting CVD according to the Random Forest model. Here’s a summary of the key features and their importance:
· Stroke: The history of stroke is the most significant factor.
· BMI (Body Mass Index): Higher BMI indicates higher risk.
· SYSBP (Systolic Blood Pressure): Elevated systolic blood pressure is a critical indicator.
· TOTCHOL (Total Cholesterol): Higher cholesterol levels contribute to the risk.
· GLUCOSE: Higher glucose levels are also important in the prediction.
· AGE: Older age increases the risk of CVD.
· DIABP (Diastolic Blood Pressure): Elevated diastolic blood pressure plays a role.
· HEARTRTE (Heart Rate): Higher heart rate is a contributing factor.
· CIGPDAY (Cigarettes Per Day): The number of cigarettes smoked per day impacts the risk.
· BPMEDS (Blood Pressure Medication): Use of BP medication is taken into account.
· HYPERTEN (Hypertension): Having hypertension is a minor but notable factor.
· DIABETES: The presence of diabetes is a minor factor in this prediction.
· CURSMOKE (Current Smoker): Whether the individual is currently smoking has the least impact compared to other factors.
Receiver Operating Characteristic (ROC) Curve:
The ROC (Receiver Operating Characteristic) curve illustrates the performance of the models. The AUC (Area Under the Curve) value is 0.93, which indicates that the model has a high level of accuracy in distinguishing between individuals who will develop CVD and those who will not.
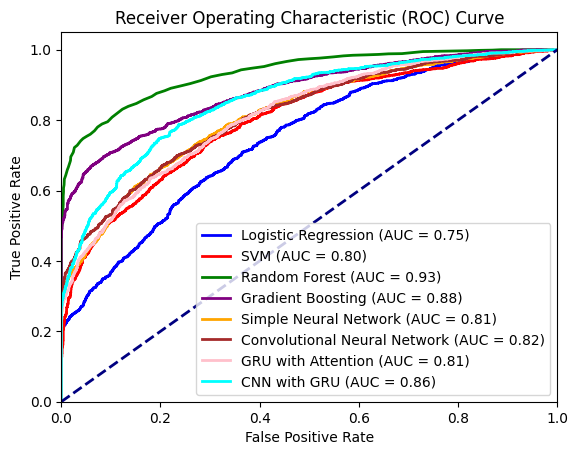
Analysis:
1- Random Forest: With an AUC of 0.93, the Random Forest model continues to outperform the other models, further solidifying its status as the best single model for this dataset.
2- Gradient Boosting Machine: The ROC AUC has increased to 0.88, indicating even stronger predictive performance.
3- Deep Learning Models: Significant improvements are observed in the deep learning models, particularly the CNN with GRU, which now has an AUC of 0.86.
4- Traditional Machine Learning Models: Logistic Regression and SVM have also improved substantially, with ROC AUCs of 0.75 and 0.80, respectively.
Recommendations:
1- Model Deployment: Continue with the Random Forest and the stacking ensemble model for deployment, as they provide the best performance.
2- Feature Engineering: The addition of new features has proven beneficial. Consider exploring additional relevant features if available.
3- Continuous Improvement: Regularly update the model with new data and re-evaluate to ensure sustained performance.