Heart Failure Prediction
by Machine Learning, Deep Learning vs. Gen AI and Stacking Gen AI Models
Heart failure is one of the leading causes of morbidity and mortality in the world; thus, there is a need to identify it as early as possible for better patient outcomes. Although traditional machine learning (ML) and neural network models demonstrate some predictive power, they most easily fail when confronting such complex and imbalanced healthcare data, compromising their reliability and generalizability. Therefore, this research presents a new Stacking Generative AI model that fills these gaps when it incorporates Generative Adversarial Networks (GAN) with Random Forest (RF), Gradient Boosting Machine (GBM), Extreme Gradient Boosting Machine (xGBM), and Convolutional Neural Networks (CNNs). The Stacking Gen AI model has been tested across seven datasets, ranging from 303 to nearly 400,000 records. In all cases, it consistently outperformed individual models, achieving an impressive accuracy of 98% and an ROC AUC of 99.9% on a dataset of 1,025 records. This robust performance demonstrates the model’s unique capability to capture complex data patterns across varied sample sizes, making it highly suitable for clinical applications. A vital advantage of this approach lies in the GAN’s ability to generate synthetic data, addressing class imbalance—a common issue in healthcare datasets—and enhancing model robustness for underrepresented patient subgroups. This innovative stacking method shows promise for heart failure prediction and broader healthcare applications, where reliable, scalable predictive models are crucial. Future research should explore its potential in diverse medical environments to optimize personalized patient care.
The data
The dataset originally comes from the CDC and is a major part of the Behavioral Risk Factor Surveillance System (BRFSS), which conducts annual telephone surveys to collect data on the health status of U.S. residents. As described by the CDC: “Established in 1984 with 15 states, BRFSS now collects data in all 50 states, the District of Columbia, and three U.S. territories. BRFSS completes more than 400,000 adult interviews each year, making it the world’s largest continuously conducted health survey system. The most recent dataset includes data from 2023. In this dataset, I noticed many factors (questions) that directly or indirectly influence heart disease, so I decided to select the most relevant variables from it. I also decided to share with you two versions of the most recent dataset: with NaNs and without it.
Web application
Design and implement an interactive web application to facilitate the interpretation of the model’s predictions. This web application provides a comprehensive overview of how different features contribute to cardiovascular disease (CVD) predictions and helps clinicians and researchers better understand the model’s decision-making process.
Research Publication
The research “Advancing Heart Failure Prediction: A Comparative Study of Machine Learning, Deep Learning, Neural Networks, and Stacking Generative AI Models,” 2025. Achieved 98% predictive accuracy. Extended methodologies to diabetes, stroke, lung, and breast cancer datasets with similar outcomes.
Risk Factors / Featured Factor Importances
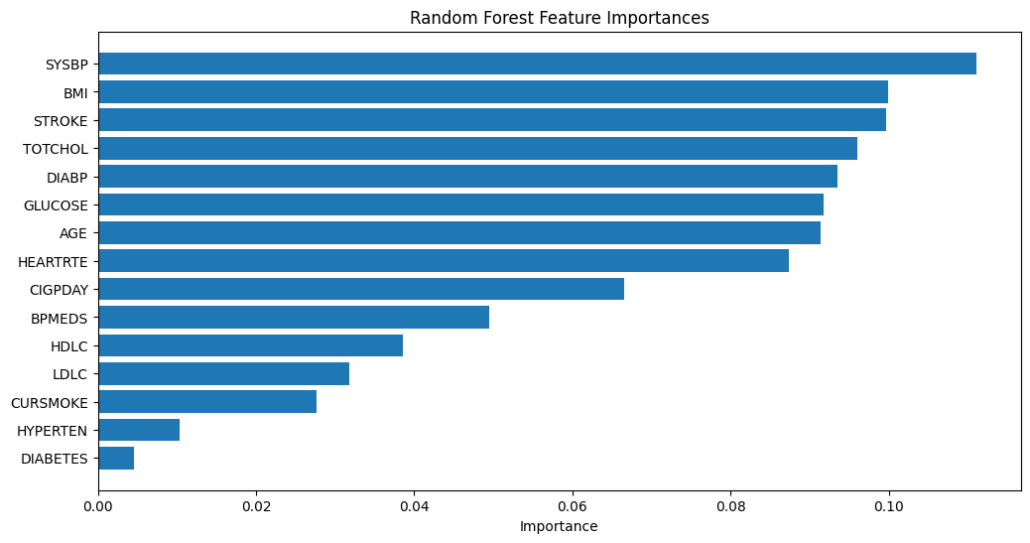
The feature importance chart highlights which factors (features) are most influential in predicting CVD according to the Random Forest model. Here’s a summary of the key features and their importance:
- Systolic Blood Pressure (SYSBP):
- Importance: Highest
- Interpretation: High systolic blood pressure is a significant predictor of CVD. Elevated blood pressure can cause damage to the arteries and heart, leading to increased risk of heart disease.
- Body Mass Index (BMI):
- Importance: High
- Interpretation: BMI is a measure of body fat based on height and weight. Higher BMI indicates obesity, which is a major risk factor for CVD due to its association with high blood pressure, diabetes, and high cholesterol.
- Stroke:
- Importance: High
- Interpretation: A history of stroke significantly increases the risk of future cardiovascular events. It indicates underlying issues such as hypertension and atherosclerosis.
- Total Cholesterol (TOTCHOL):
- Importance: High
- Interpretation: Elevated total cholesterol levels contribute to the build-up of plaques in arteries, increasing the risk of heart attacks and strokes.
- Diastolic Blood Pressure (DIABP):
- Importance: Moderate
- Interpretation: While less critical than systolic blood pressure, high diastolic blood pressure still indicates cardiovascular stress and risk.
- Glucose:
- Importance: Moderate
- Interpretation: High glucose levels are associated with diabetes, which is a major risk factor for CVD. Diabetes can lead to damage of blood vessels and nerves controlling the heart.
- Age:
- Importance: Moderate
- Interpretation: Age is a non-modifiable risk factor. The risk of CVD increases with age due to cumulative effects of risk factors and age-related changes in the cardiovascular system.
- Heart Rate (HEARTRTE):
- Importance: Moderate
- Interpretation: Elevated resting heart rate can be a sign of cardiovascular stress and potential heart problems.
- Cigarettes Per Day (CIGPDAY):
- Importance: Moderate
- Interpretation: Smoking is a well-known risk factor for CVD. It damages the lining of the arteries, leading to atherosclerosis and increasing the risk of heart attacks and strokes.
- On Blood Pressure Medication (BPMEDS):
- Importance: Moderate
- Interpretation: Being on blood pressure medication indicates the presence of hypertension, which is a significant risk factor for CVD.
- High-Density Lipoprotein Cholesterol (HDLC):
- Importance: Low
- Interpretation: HDL cholesterol is known as “good” cholesterol. Higher levels are protective against heart disease, so lower importance in predicting CVD is expected as it’s a protective factor.
- Low-Density Lipoprotein Cholesterol (LDLC):
- Importance: Low
- Interpretation: LDL cholesterol is known as “bad” cholesterol. Higher levels can lead to plaque build-up in arteries, increasing the risk of CVD.
- Current Smoker (CURSMOKE):
- Importance: Low
- Interpretation: Current smoking status is a risk factor for CVD. Smoking damages the cardiovascular system, leading to increased risk.
- Hypertension (HYPERTEN):
- Importance: Low
- Interpretation: Hypertension is a major risk factor for CVD. It causes damage to the blood vessels and heart over time.
- Diabetes (DIABETES):
- Importance: Lowest
- Interpretation: Diabetes is a significant risk factor for CVD. It leads to high blood glucose levels, which damage the blood vessels and heart.
Summary
The Random Forest model identifies Systolic Blood Pressure, BMI, Stroke, and Total Cholesterol as the most critical predictors of cardiovascular disease. These factors are essential for medical professionals to monitor and manage in patients to reduce the risk of CVD. Other factors such as age, glucose levels, smoking, and hypertension also contribute significantly to the risk, highlighting the multifactorial nature of cardiovascular disease.
Overview
The performance of the Stacking Gen AI model on the 400,000-record dataset, as shown in the provided table and ROC plot, can be summarized as follows:
| Dataset | Performance | Model | Proposed Model | ||||||||
| LR | RF | GBM | XGB | CNN | GRU w/ Attention | CNN w/ GRU | Stacking ML+DL | Gen AI | Stacking Gen AI | ||
| 400,000 | Accuracy | 77 | 90 | 77 | 80 | 78 | 79 | 80 | 90 | 95 | 96 |
| ROC AUC | 84 | 96 | 85 | 88 | 86 | 87 | 88 | 96 | 99 | 99 | |
- Accuracy: The Stacking Gen AI model achieves a top-tier accuracy of 96%, which is the highest among all listed models. This high accuracy indicates that the model is highly effective in making correct predictions on the dataset compared to other machine learning and deep learning models, such as Random Forest (90%), Gradient Boosting (77%), and even the baseline Stacking model (90%).
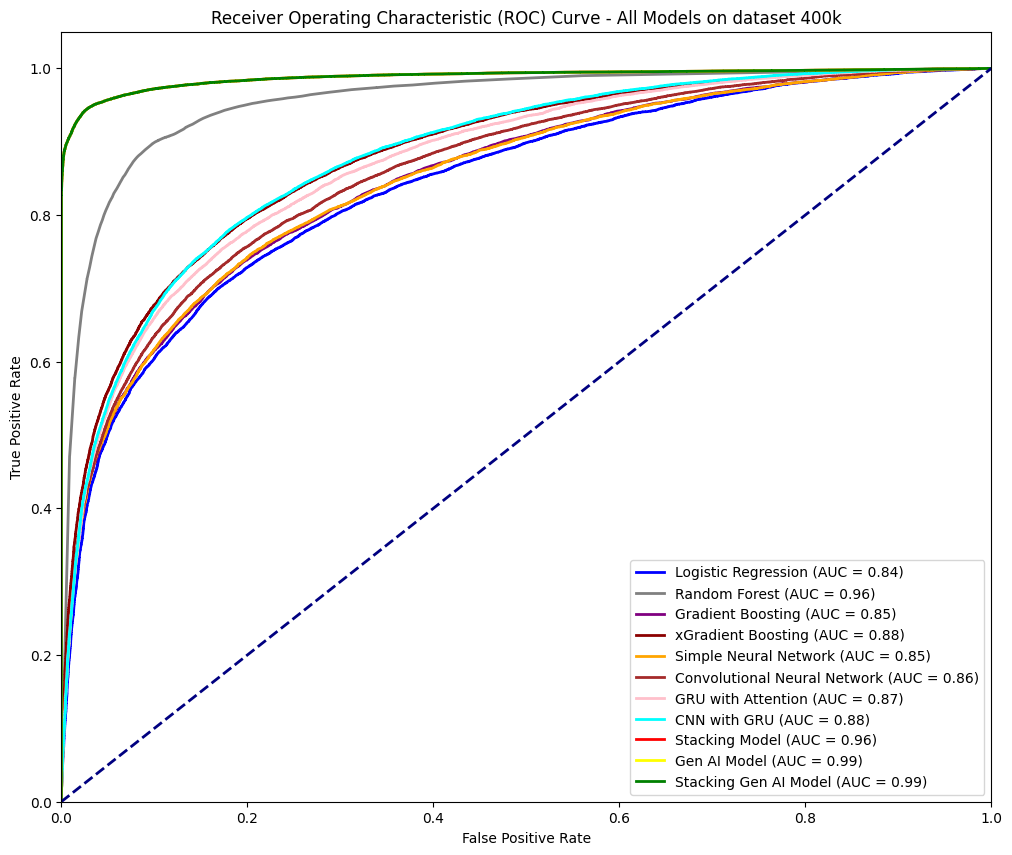
- ROC AUC Score: The model also reaches a near-perfect ROC AUC of 0.99, tying with the Gen AI Model. This high ROC AUC value means the Stacking Gen AI model has an excellent ability to distinguish between the positive and negative classes across various threshold settings. A ROC AUC of 0.99 implies that the model can achieve high true positive rates while keeping false positive rates low, which is critical in medical predictions like heart failure.
- Comparison to Other Models:
- The Logistic Regression model has a significantly lower ROC AUC (0.84) and accuracy (77%), demonstrating the limitation of simpler, linear models on complex datasets.
- Random Forest (RF) performs relatively well, with an ROC AUC of 0.96 and an accuracy of 90%, but it is still outperformed by the Stacking Gen AI model. This indicates that the integration of multiple models in Stacking Gen AI provides added predictive strength.
- Deep learning models like CNN with GRU and GRU with Attention show ROC AUC scores of 0.88 and 0.87, respectively. While these models perform well, they don’t reach the effectiveness of the Stacking Gen AI model, likely due to the additional power of GAN-generated synthetic data for class balancing in the Stacking Gen AI approach.
- Impact of GAN Integration:
- The GAN-generated data within the Stacking Gen AI model addresses class imbalance, improving minority class detection. This is evident in the high ROC AUC score, which reflects the model’s balanced performance across both majority and minority classes, a common challenge in medical datasets.
- Overall Performance on the ROC Curve:
- On the ROC curve, the Stacking Gen AI model (indicated by the bright green line) consistently remains near the top-left corner, confirming its high sensitivity and specificity. This positioning visually reinforces the model’s strong predictive capability and minimal compromise between true positives and false positives.
Conclusion
The findings in this study position the Stacking Generative AI model as a significant hybrid approach in predictive modeling for heart disease. By integrating Generative AI techniques with traditional machine learning models such as Random Forest (RF), Gradient Boosting Machines (GBM), and Extreme Gradient Boosting (xGBM), alongside deep learning architectures such as Convolutional Neural Networks (CNN) and Recurrent Neural Networks (RNN), the model effectively combines the strengths of these methods to achieve superior predictive accuracy. The inclusion of Generative AI, particularly Generative Adversarial Networks (GANs), enhances the model’s ability to perform data augmentation and address class imbalances, which are common and critical challenges in healthcare datasets.
The model consistently demonstrated high accuracy and ROC AUC scores across datasets ranging from 303 to 400,000 records; it has been implemented and proved in my comprehensive research for the dissertation. For smaller datasets, such as the 303-record dataset, it achieved an ROC AUC of 0.99, outperforming standalone models like RF, CNN, and xGBM. On larger datasets, such as the 400,000-record dataset, the model maintained its strong performance with an accuracy of 96% and an ROC AUC of 0.99. These results confirm the model’s scalability and generalizability, making it highly effective for small-scale and large-scale clinical applications.
A key strength of this approach lies in the integration of Generative AI within the stacking framework. The use of GANs enables the generation of synthetic data to balance underrepresented classes, ensuring more robust training and improving the model’s ability to generalize across diverse and imbalanced datasets. This feature is particularly advantageous in healthcare, where imbalanced datasets are prevalent, and accurate predictions for minority classes, such as high-risk patients, are essential for improving clinical outcomes.
The Stacking Generative AI model’s hybrid structure leverages the strengths of traditional machine learning and deep learning methods. While traditional models like RF and xGBM excel in analyzing structured data and assessing feature importance, deep learning models like CNNs and RNNs effectively capture nonlinear relationships and temporal patterns. The seamless integration of these approaches allows the Stacking Generative AI model to provide a comprehensive solution for heart disease prediction.
Overall, these findings underscore the practical relevance of the Stacking Generative AI model for healthcare applications. Its adaptability to diverse dataset sizes and structures and consistent high performance make it a valuable tool for clinical decision-making. The model’s ability to improve predictive accuracy and address key challenges in healthcare data highlights its potential to advance heart disease prediction and management. Furthermore, this work lays the groundwork for future research exploring the broader application of Generative AI and hybrid models in medical prediction tasks.
 howardnguyen
howardnguyen