Naive Bayes Model
a simple yet powerful algorithm for classification tasks
Naive Bayes is a simple probabilistic classifier based on Bayes’ theorem with the “naive” assumption of independence between features. Despite its simplicity, Naive Bayes classifiers often perform well in practice, especially for text classification tasks. They are fast to train and require minimal tuning of hyperparameters.
Here’s a brief overview of Naive Bayes:
- Bayes’ Theorem: Naive Bayes is based on Bayes’ theorem, which calculates the probability of a hypothesis given the evidence. In the context of classification, it calculates the probability of each class given the input features.
- Independence Assumption: Naive Bayes assumes that the features are conditionally independent given the class label. While this assumption may not hold true in many real-world scenarios, Naive Bayes can still perform well, especially for text classification tasks.
- Types of Naive Bayes: There are different variants of Naive Bayes classifiers, including:
- Gaussian Naive Bayes: Assumes that features follow a Gaussian distribution.
- Multinomial Naive Bayes: Suitable for text classification with discrete features (e.g., word counts).
- Bernoulli Naive Bayes: Similar to Multinomial Naive Bayes but works with binary features (e.g., presence or absence of words).
- Classification: Naive Bayes calculates the probability of each class given the input features using Bayes’ theorem and selects the class with the highest probability as the predicted class.
Sample Code in Python
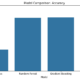
from sklearn.datasets import fetch_20newsgroupsfrom sklearn.feature_extraction.text import CountVectorizerfrom sklearn.naive_bayes import MultinomialNBfrom sklearn.pipeline import make_pipelinefrom sklearn.model_selection import train_test_splitfrom sklearn import metrics# Load the 20 Newsgroups dataset (a popular text dataset)data = fetch_20newsgroups()# Split the dataset into training and testing setsX_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.25, random_state=42)# Create a pipeline with CountVectorizer for feature extraction and MultinomialNB for classificationmodel = make_pipeline(CountVectorizer(), MultinomialNB())# Train the modelmodel.fit(X_train, y_train)# Predict the labels for the test sety_pred = model.predict(X_test)# Calculate accuracyaccuracy = metrics.accuracy_score(y_test, y_pred)print("Accuracy:", accuracy)# Classification reportprint(metrics.classification_report(y_test, y_pred, target_names=data.target_names))Results of this classification report

In this example:
– We use the 20 Newsgroups dataset, a collection of approximately 20,000 newsgroup documents across 20 different categories.
– We split the dataset into training and testing sets.
– We create a pipeline consisting of CountVectorizer for converting text documents into a matrix of token counts and MultinomialNB for classification.
– We train the model on the training data and evaluate its performance on the test data.
Finally, we print the accuracy and classification report containing precision, recall, and F1-score for each class.
This is a basic example to demonstrate the usage of Multinomial Naive Bayes for text classification. Depending on your specific use case, you may need to adjust the preprocessing steps, feature extraction methods, or hyperparameters to achieve optimal performance.