clustering and segmentation are techniques used in data analysis to group data points based on similarities, but they are applied in different contexts and have distinct goals.
clustering and segmentation are techniques used in data analysis to group data points based on similarities, but they are applied in different contexts and have distinct goals.
The Autoregressive Integrated Moving Average (ARIMA) model is a widely used time series forecasting model that combines autoregression (AR), differencing (I for Integrated), and moving averages (MA) to capture various aspects of time series data. ARIMA is effective for modeling time series with trend and seasonality components.
Here’s an overview of the components and structure of the ARIMA model:
- Autoregressive (AR) Component (p): The AR component represents the relationship between the current value of the time series and its past values. It incorporates lagged values to capture autocorrelation. An AR(p) model uses ‘p’ past values.
- Integrated (I) Component (d): The I component represents differencing, which is applied to make the time series stationary. If the original time series is non-stationary (e.g., it has a trend), differencing is performed to remove the trend. The ‘d’ parameter indicates the number of differences required to achieve stationarity.
- Moving Average (MA) Component (q): The MA component models the relationship between the current value and past forecast errors. An MA(q) model uses ‘q’ past forecast errors.
The general form of an ARIMA model can be expressed as ARIMA(p, d, q):
Xt = c + ϕ1Xt−1 + ϕ2Xt−2 + … + ϕpXt−p – ϕ1ϵt−1 – ϕ1ϵt−2 – … – ϕqϵt−q + ϵt
- Xt is the value at time “t.”
- c is a constant or intercept.
- ϕ1, ϕ2, …, ϕp are the autoregressive coefficients.
- Xt−1, Xt−2, …, Xt−p are the lagged values.
- ϵt is the white noise or error term.
To use ARIMA for time series forecasting, you need to determine the appropriate values of ‘p,’ ‘d,’ and ‘q’ based on the characteristics of your data. This typically involves visual inspection of the data, ACF (AutoCorrelation Function) and PACF (Partial AutoCorrelation Function) plots, and statistical tests for stationarity (e.g., Augmented Dickey-Fuller).
Once you’ve determined the ARIMA order (p, d, q), you can fit the model to your time series data and use it for forecasting future values. Libraries like statsmodels in Python provide tools for ARIMA modeling and forecasting.
Here’s a simplified Python code snippet to fit and forecast with an ARIMA model:
import pandas as pd
import statsmodels.api as sm
# Load your time series data into a pandas DataFrame
# Replace this with your own time series data
# Example: data = pd.read_csv('your_data.csv')
# Fit an ARIMA model
model = sm.tsa.ARIMA(data, order=(p, d, q))
results = model.fit()
# Forecast future values
forecast = results.predict(start=len(data), end=len(data) + n-1, dynamic=False)
Replace p, d, q, and n with your chosen ARIMA order and the number of periods you want to forecast into the future. The forecast variable will contain the forecasted values.
PyTorch is a versatile deep learning framework with a wide range of applications across various domains. Some of its notable applications include:
- Computer Vision:
- Image Classification: PyTorch is commonly used for building and training convolutional neural networks (CNNs) for tasks like image classification, where models learn to classify objects in images.
- Object Detection: It’s used for creating object detection models to locate and classify objects within images or video streams. Popular architectures like Faster R-CNN and YOLO are often implemented in PyTorch.
- Semantic Segmentation: PyTorch is used for semantic segmentation tasks, where each pixel in an image is classified into a specific category or object class.
- Face Recognition: Deep learning models for face recognition, face detection, and facial feature analysis are often implemented using PyTorch.
- Natural Language Processing (NLP):
- Text Classification: PyTorch is applied to text classification tasks, such as sentiment analysis, spam detection, and topic categorization.
- Named Entity Recognition (NER): It’s used to build models that can identify and classify named entities (e.g., names of people, places, organizations) in text data.
- Machine Translation: PyTorch has been used to develop machine translation models like sequence-to-sequence models with attention mechanisms.
- Language Generation: It’s utilized for language generation tasks, including text generation, chatbots, and dialogue systems.
- Reinforcement Learning (RL):
- PyTorch is widely used for implementing and training reinforcement learning algorithms, including deep reinforcement learning techniques. Libraries like OpenAI’s Gym and Stable Baselines use PyTorch as their backend for RL experiments.
- Generative Models:
- PyTorch is popular for generative modeling tasks, including Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs), which can generate new data samples.
- Recommendation Systems:
- PyTorch is employed to build recommendation systems that provide personalized recommendations to users based on their historical preferences and behaviors.
- Healthcare and Medical Imaging:
- PyTorch is used in medical image analysis tasks, including disease diagnosis, lesion detection, and medical image segmentation.
- Autonomous Vehicles:
- In the field of autonomous vehicles, PyTorch is used for tasks such as object detection, lane detection, and perception systems.
- Time Series Analysis:
- PyTorch is applied to time series forecasting and anomaly detection tasks, which are important in finance, manufacturing, and other industries.
- Scientific Research:
- PyTorch is used in various scientific research areas, including physics, astronomy, biology, and climate science, for tasks like data analysis, simulations, and modeling.
- Artificial Intelligence Research:
- PyTorch is widely adopted in AI research to develop and experiment with new deep learning architectures and algorithms.
These are just a few examples of the diverse range of applications for PyTorch. Its flexibility and ease of use make it suitable for a wide array of machine learning and deep learning tasks in both research and industry.
PyTorch is an open-source machine learning framework developed by Facebook’s AI Research lab (FAIR). It is widely used for various machine learning and deep learning tasks, including neural networks, natural language processing, computer vision, and more. PyTorch is known for its flexibility, ease of use, and dynamic computation graph, which makes it a popular choice among researchers and developers.
Here are some key features and characteristics of PyTorch:
- Dynamic Computational Graph:
- PyTorch uses dynamic computation graphs, which means that the graph is built on-the-fly as operations are performed. This dynamic nature allows for more flexibility when defining and modifying models compared to static graph frameworks.
- Pythonic:
- PyTorch is designed to be Pythonic, which makes it intuitive and easy to learn for Python developers. It integrates well with Python libraries and tools.
- Tensors:
- PyTorch provides a powerful multi-dimensional array called a “tensor,” which is similar to NumPy arrays but with additional features optimized for deep learning.
- Automatic Differentiation:
- PyTorch includes a built-in automatic differentiation system called Autograd. It tracks operations on tensors and can automatically compute gradients, making it suitable for gradient-based optimization algorithms like backpropagation.
- Neural Network Library:
- PyTorch includes a high-level neural network library with pre-defined layers, loss functions, and optimization algorithms, making it convenient for building and training neural networks.
- Support for GPUs:
- PyTorch has native support for running computations on GPUs, which can significantly speed up training deep learning models.
- Libraries and Ecosystem:
- PyTorch has a rich ecosystem of libraries and tools, including torchvision for computer vision, torchtext for natural language processing, and many third-party libraries and extensions created by the community.
- Active Community:
- PyTorch has a growing and active community of researchers and developers who contribute to its development, create tutorials, and provide support.
- Deployment Options:
- PyTorch provides several options for deploying models in production, including PyTorch Mobile for mobile devices and PyTorch Serving for serving models in a production environment.
- Research and Industry Adoption:
- PyTorch is widely adopted in both research and industry, and it is commonly used in academia for cutting-edge research in machine learning and deep learning.
In summary, PyTorch is a versatile and powerful deep learning framework that combines flexibility and ease of use, making it a popular choice for building and training machine learning models. It has played a significant role in advancing the field of deep learning and continues to be a prominent framework in the machine learning community.
Learn more about PyTorch’s applications
Machine learning can be broadly categorized into three main types: supervised learning, unsupervised learning, and reinforcement learning. Each type serves different purposes and is used in various applications:
- Supervised Learning: In supervised learning, the algorithm is trained on a labeled dataset, which means that the input data is paired with the correct output or target. The goal of supervised learning is to learn a mapping from inputs to outputs. It involves training the model to make predictions or classifications based on input features, and then evaluating its performance by comparing its predictions to the true labels in the training data.
Common supervised learning algorithms include:
-
- Linear Regression: Used for regression tasks to predict continuous numerical values.
- Logistic Regression: Used for binary classification problems.
- Decision Trees, Random Forests: Versatile algorithms for classification and regression.
- Support Vector Machines (SVM): Useful for both classification and regression tasks.
- Neural Networks: Deep learning models capable of handling complex tasks.
- Unsupervised Learning: Unsupervised learning involves working with unlabeled data, where the algorithm tries to find patterns, structure, or relationships within the data without any predefined target. The primary goal is to uncover hidden structures or groupings within the data.
Common unsupervised learning algorithms include:- Clustering Algorithms: Such as k-means, hierarchical clustering, and DBSCAN, which group data points based on similarity.
- Dimensionality Reduction Techniques: Like Principal Component Analysis (PCA) and t-Distributed Stochastic Neighbor Embedding (t-SNE), used to reduce the number of features while retaining important information.
- Generative Models: Such as Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs), used for data generation and synthesis.
- Reinforcement Learning: Reinforcement learning is a type of machine learning where an agent interacts with an environment and learns to make a sequence of decisions to maximize a cumulative reward. It is commonly used in tasks where an agent learns to take actions in a dynamic environment to achieve a specific goal.
Components of reinforcement learning include:- Agent: The learner or decision-maker.
- Environment: The external system with which the agent interacts.
- Actions: The set of possible moves or decisions the agent can make.
- Rewards: Feedback provided by the environment to evaluate the agent’s actions.
- Policy: The strategy or set of rules the agent uses to select actions.
Common reinforcement learning algorithms include:
-
- Q-Learning: Used for discrete action spaces.
- Deep Q-Networks (DQN): Combines Q-learning with deep neural networks.
- Policy Gradient Methods: Directly learn the policy to maximize rewards.
- Proximal Policy Optimization (PPO), Actor-Critic: Methods for more stable training.
Each type of machine learning has its own set of applications and is suitable for different problem domains. Choosing the right type of machine learning depends on the nature of your data, the problem you want to solve, and the available resources.
A roadmap for building machine learning systems
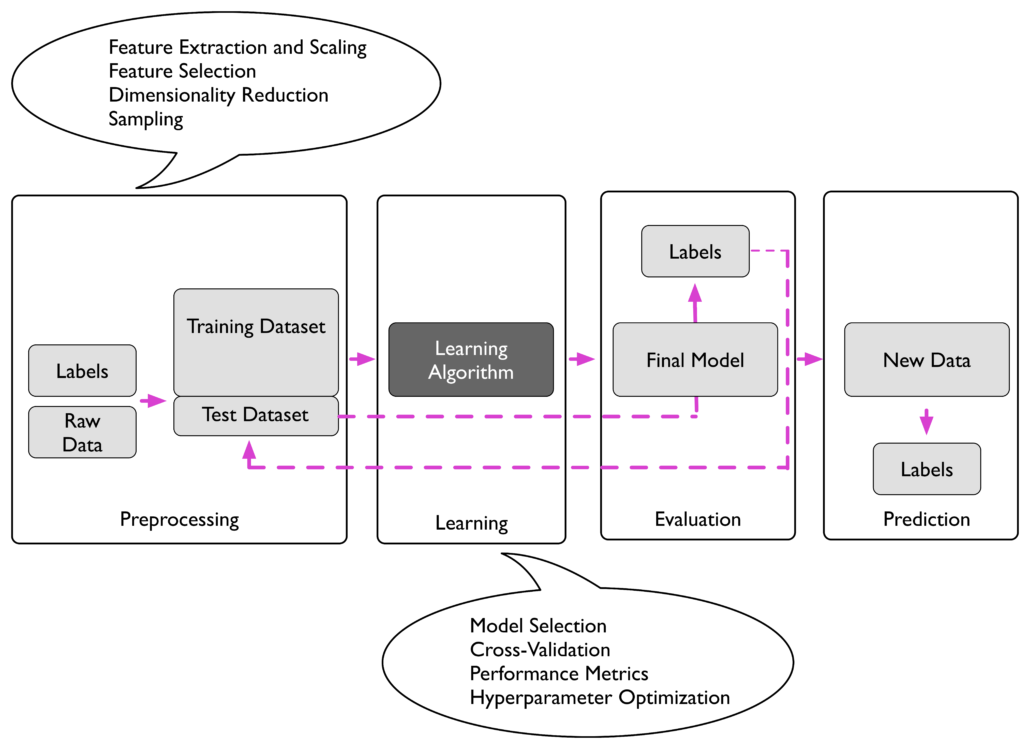
A roadmap for building machine learning systems, diagram credited from Sebastian Raschka